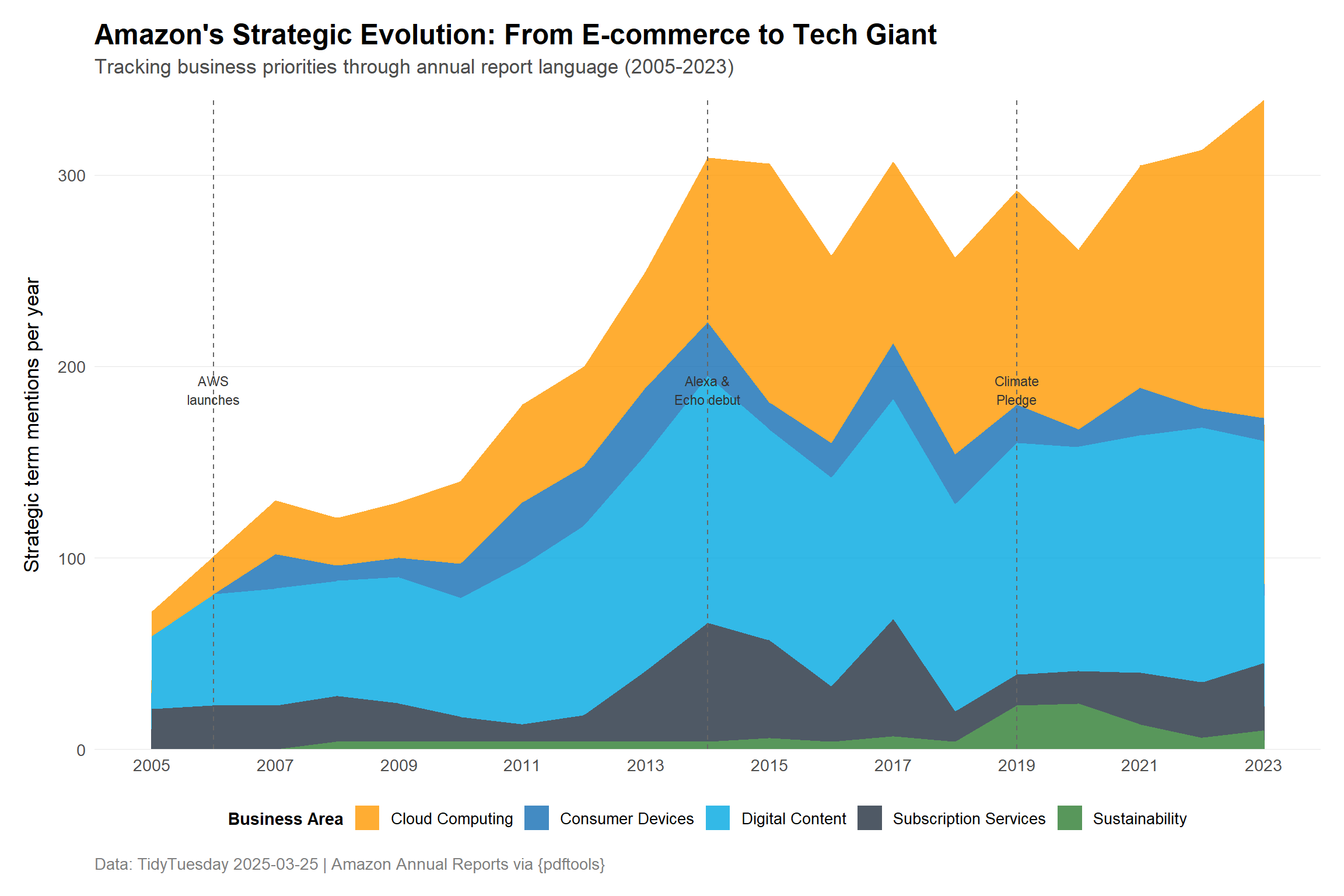
# Prepare data for streamgraph-style area plot
plot_data <- category_summary %>%
complete(year = 2005:2023, category, fill = list(mentions = 0)) %>%
arrange(year, category)
# Define category colors inspired by Amazon's brand and domain
category_colors <- c(
"Cloud Computing" = "#FF9900", # Amazon orange
"Consumer Devices" = "#146EB4", # Amazon blue
"Subscription Services" = "#232F3E", # Amazon dark
"Digital Content" = "#00A8E1", # Lighter blue
"Sustainability" = "#2E7D32" # Earth green
)
# Create plot
ggplot(plot_data, aes(x = year, y = mentions, fill = category)) +
geom_area(alpha = 0.8, position = 'stack') +
geom_vline(
xintercept = c(2006, 2014, 2019),
linetype = "dashed",
color = "gray40",
linewidth = 0.4
) +
annotate(
"text", x = 2006, y = 180,
label = "AWS\nlaunches",
family = "sans", size = 3, hjust = 0.5, vjust = 0, color = "gray20"
) +
annotate(
"text", x = 2014, y = 180,
label = "Alexa &\nEcho debut",
family = "sans", size = 3, hjust = 0.5, vjust = 0, color = "gray20"
) +
annotate(
"text", x = 2019, y = 180,
label = "Climate\nPledge",
family = "sans", size = 3, hjust = 0.5, vjust = 0, color = "gray20"
) +
scale_fill_manual(values = category_colors) +
scale_x_continuous(breaks = seq(2005, 2023, 2)) +
scale_y_continuous(expand = c(0, 0)) +
labs(
title = "Amazon's Strategic Evolution: From E-commerce to Tech Giant",
subtitle = "Tracking business priorities through annual report language (2005-2023)",
x = NULL,
y = "Strategic term mentions per year",
fill = "Business Area",
caption = "Data: TidyTuesday 2025-03-25 | Amazon Annual Reports via {pdftools}"
) +
theme_minimal(base_size = 13, base_family = "sans") +
theme(
plot.title = element_text(face = "bold", size = 18, margin = margin(b = 5)),
plot.subtitle = element_text(size = 13, color = "gray30", margin = margin(b = 15)),
plot.caption = element_text(color = "gray50", hjust = 0, margin = margin(t = 10)),
legend.position = "bottom",
legend.title = element_text(face = "bold", size = 11),
legend.text = element_text(size = 10),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
panel.grid.major.y = element_line(color = "gray90", linewidth = 0.3),
plot.margin = margin(15, 15, 15, 15),
axis.text = element_text(color = "gray30"),
axis.title.y = element_text(margin = margin(r = 10))
)