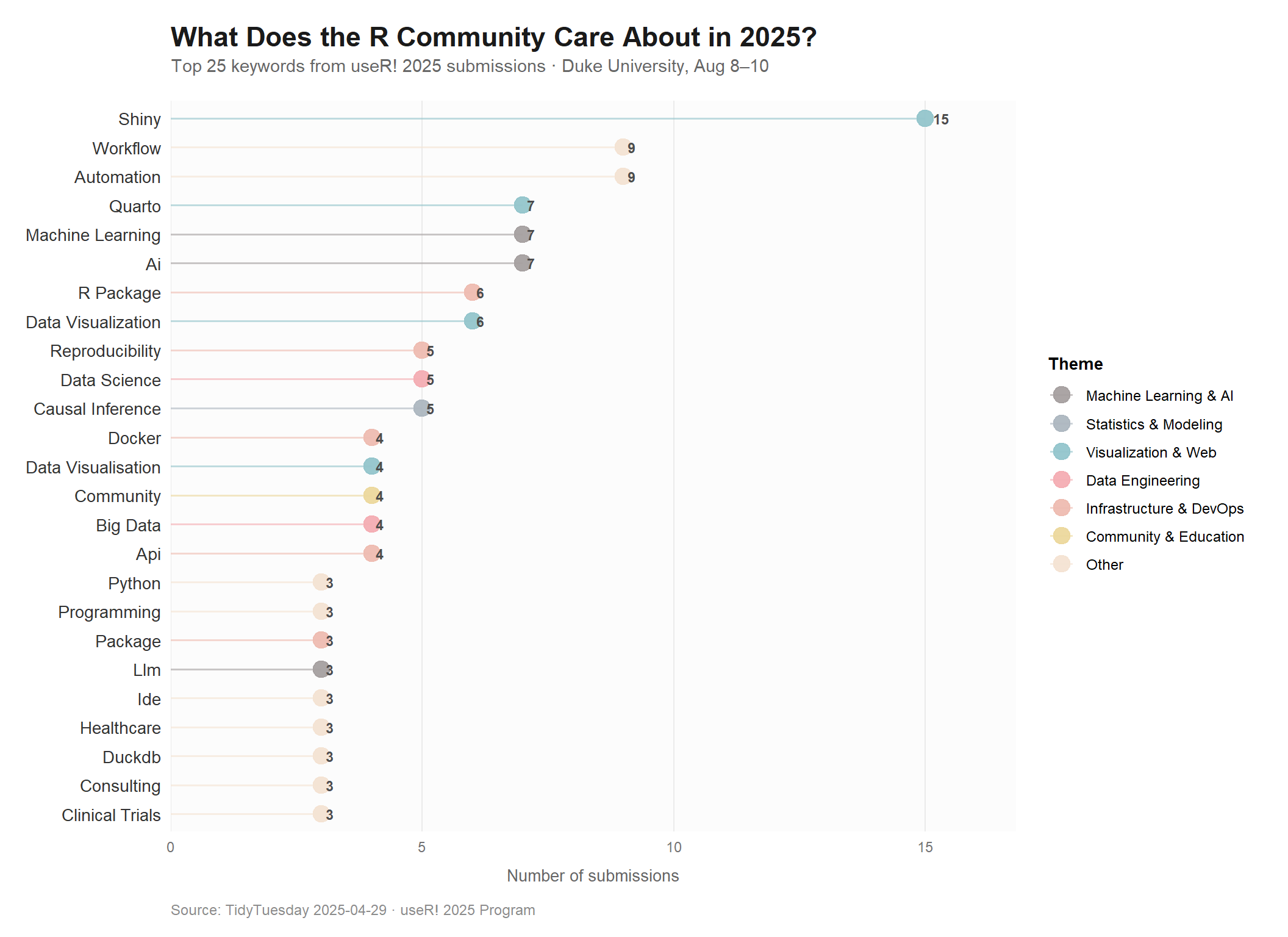
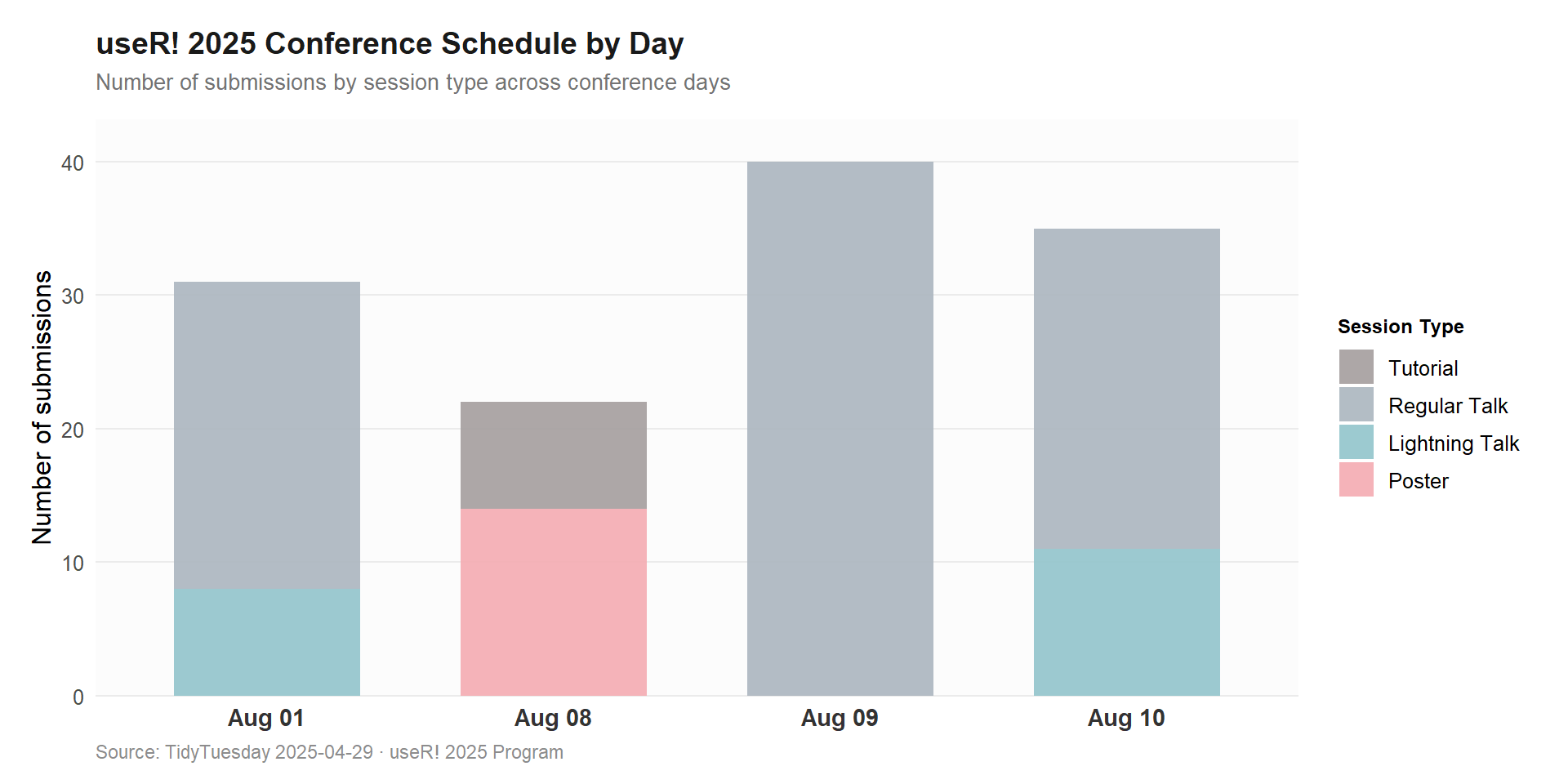
# A tibble: 20 × 1
keywords
<chr>
1 statistical programming, clinical trials data, dataset interface, workflow
2 ide, workflow, tooling
3 demography, frameworks, census data, equity ml/ai, anti-discrimination in ml…
4 automation, event-driven workflows, plumber api, github webhooks
5 marketing, statistical modelling, econometrics, measurement, regression
6 data processing, parquet, analytics, big data, storage
7 factor analysis, exploratory data analysis, dimension reduction, ordinal dat…
8 testing, behavior-driven development, test-driven development, efficient pro…
9 automation, llms, ai
10 quarto, shiny, data storytelling, interactive dashboards, visualization
11 big data, shiny, healthcare, data harmonization, rdbms
12 deep learning, machine learning, healthcare, decision making
13 data visualization, ggplot2, interactive charts, storytelling, dashboard
14 package management, infrastructure, open source
15 data sharing, data, automation, r, repository managment
16 shiny apps, dashboard, environmental science, health science, decision-makin…
17 shiny,automation,docker,webapp
18 shiny, shinyproxy, system design, microservices, docker
19 asynchronous programming, distributed computing, parallel computing, open so…
20 modules, shiny, box, api, production