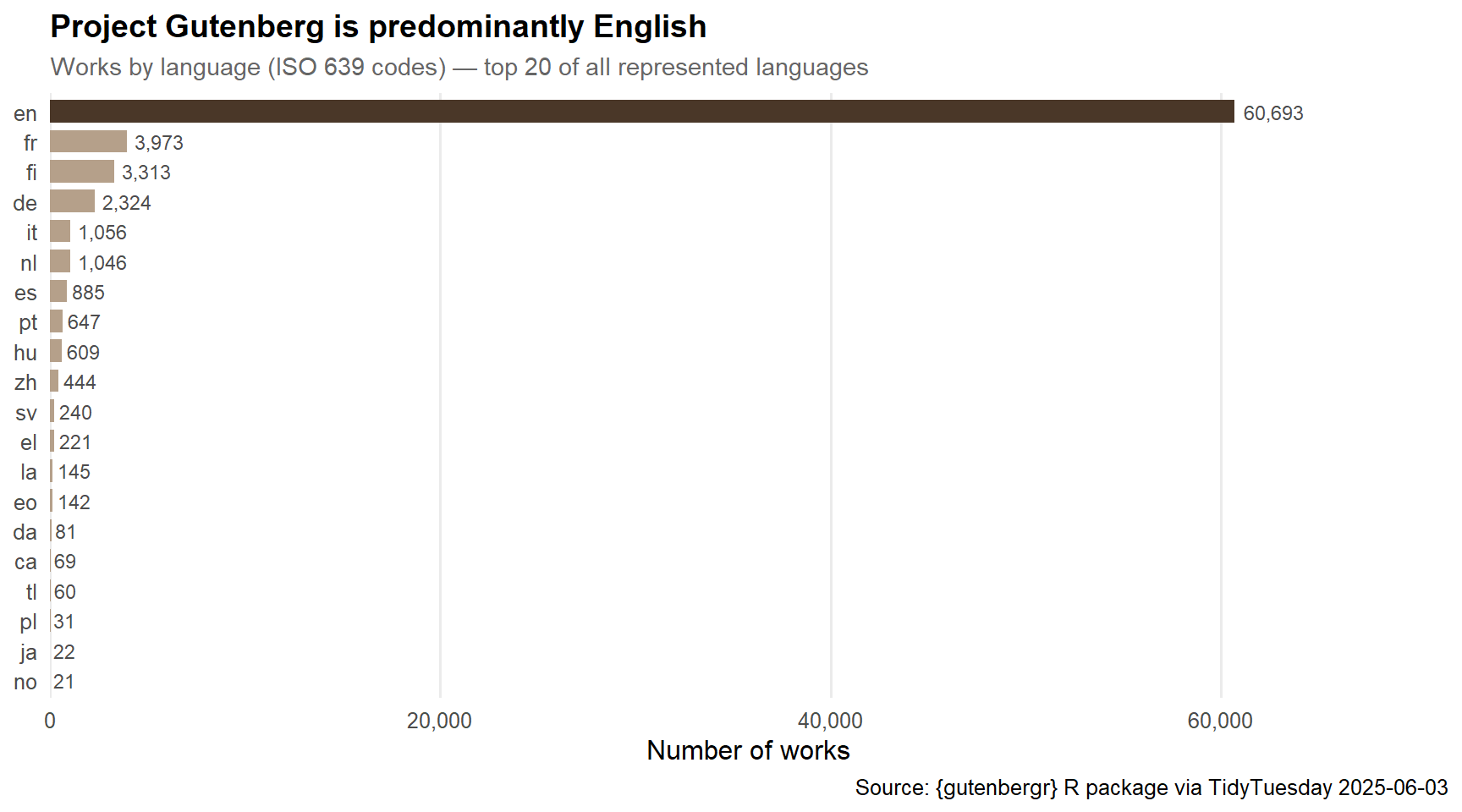
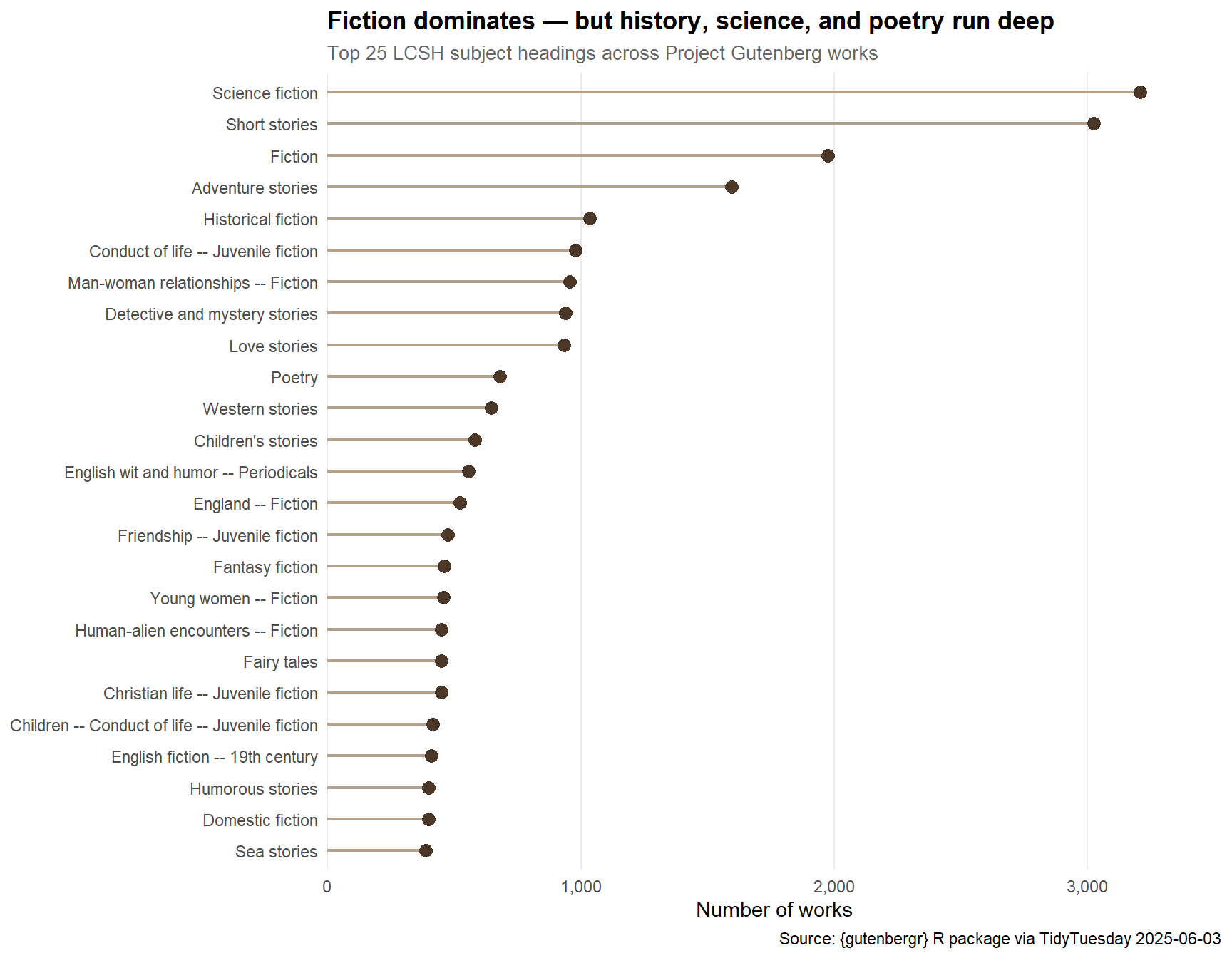
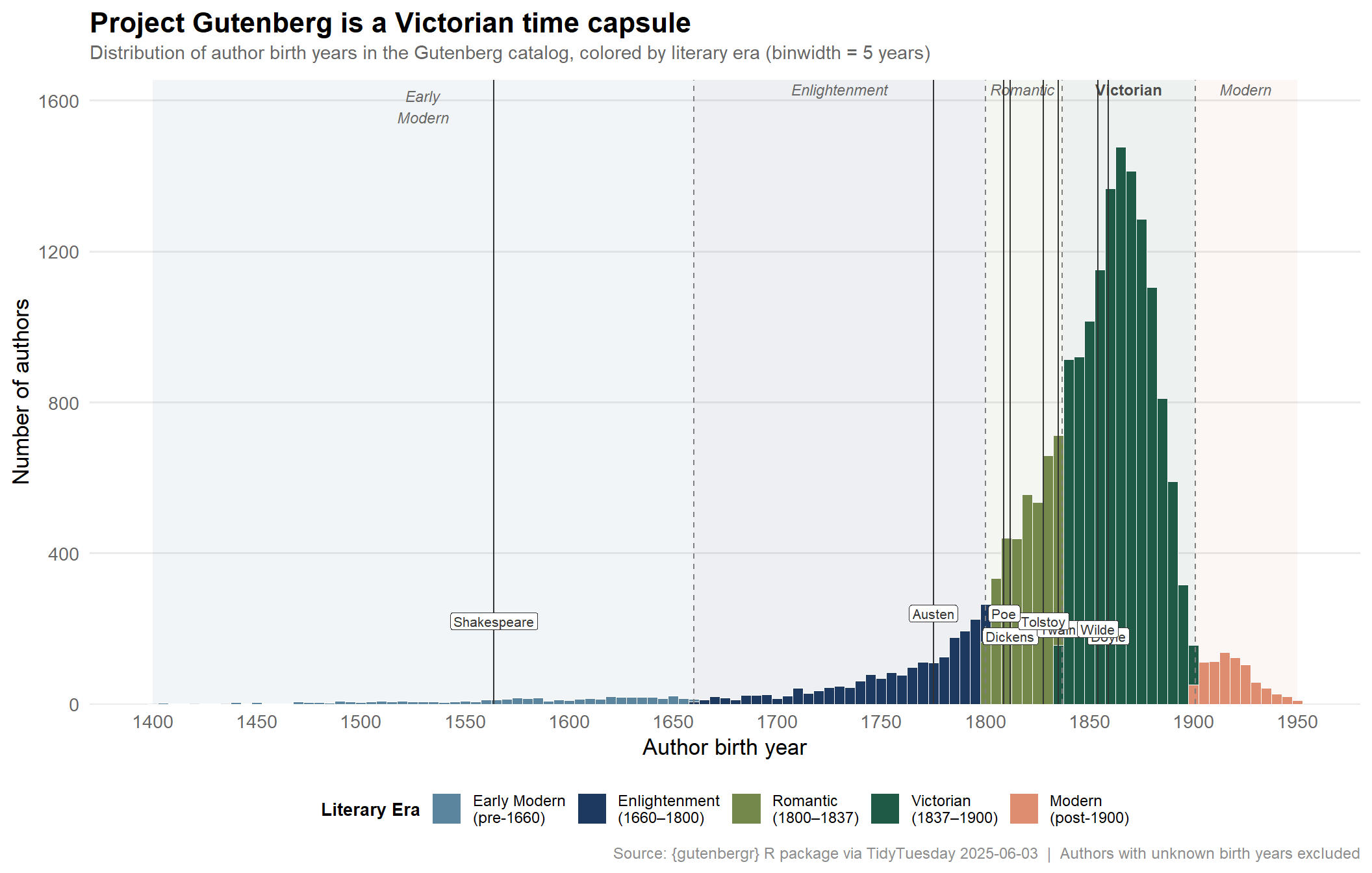
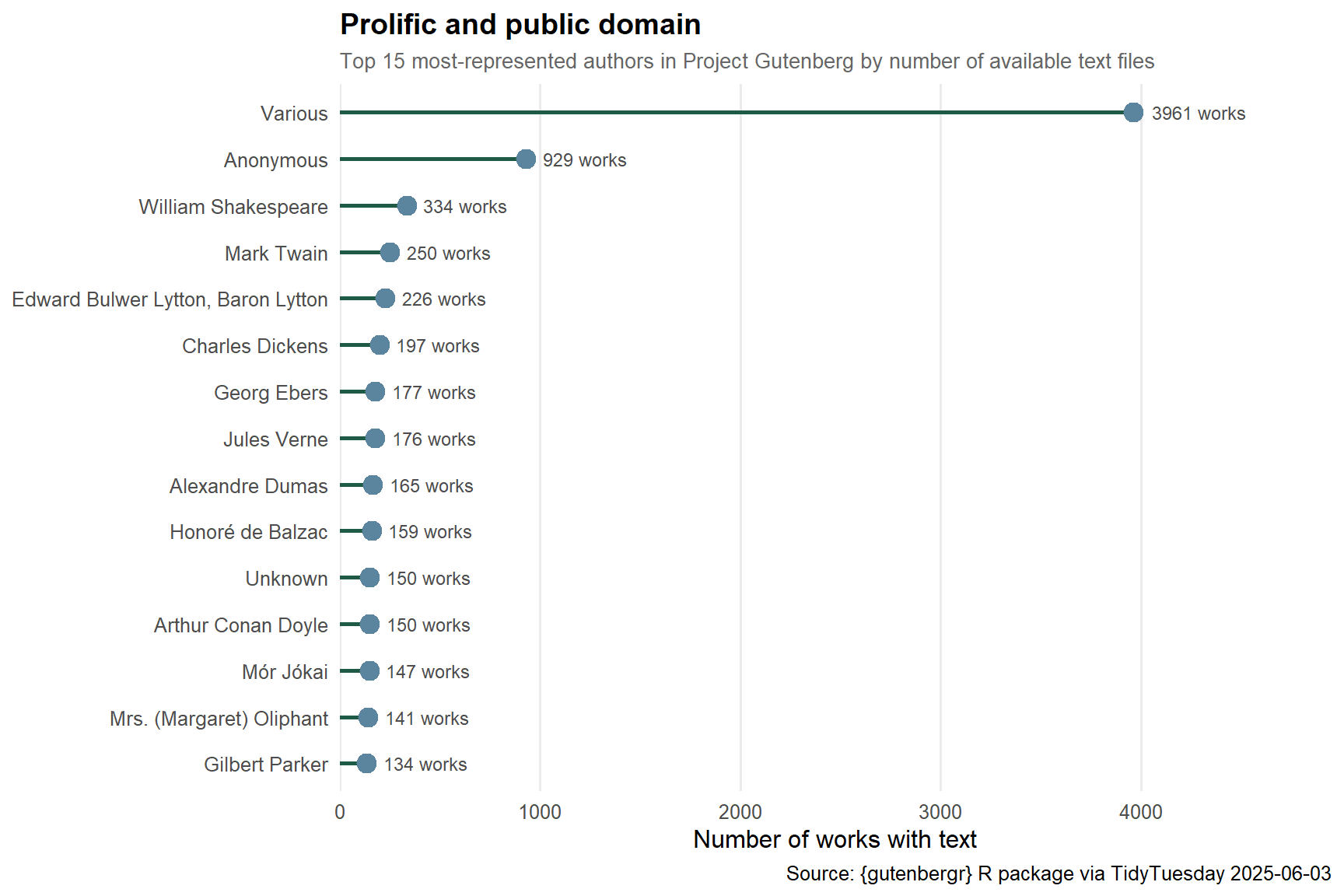
era_palette <- paletteer::paletteer_d("MetBrewer::Redon", n = 5)
era_levels <- c(
"Early Modern\n(pre-1660)",
"Enlightenment\n(1660–1800)",
"Romantic\n(1800–1837)",
"Victorian\n(1837–1900)",
"Modern\n(post-1900)"
)
# Compute a y-position for author annotations based on histogram peak
# We'll place them near the top of the plot with staggered heights
author_annotation_y <- c(180, 200, 220, 180, 200, 220, 180, 200)
# Only annotate authors we actually found
n_famous <- nrow(famous_authors)
annotation_heights <- c(180, 200, 220, 240, 180, 200, 220, 240)[seq_len(n_famous)]
p_hero <- author_era_data %>%
ggplot(aes(x = birthdate, fill = era)) +
# Background era bands for context
annotate("rect",
xmin = 1400, xmax = 1660,
ymin = 0, ymax = Inf,
fill = era_palette[1], alpha = 0.08
) +
annotate("rect",
xmin = 1660, xmax = 1800,
ymin = 0, ymax = Inf,
fill = era_palette[2], alpha = 0.08
) +
annotate("rect",
xmin = 1800, xmax = 1837,
ymin = 0, ymax = Inf,
fill = era_palette[3], alpha = 0.08
) +
annotate("rect",
xmin = 1837, xmax = 1901,
ymin = 0, ymax = Inf,
fill = era_palette[4], alpha = 0.08
) +
annotate("rect",
xmin = 1901, xmax = 1950,
ymin = 0, ymax = Inf,
fill = era_palette[5], alpha = 0.08
) +
# Histogram bars colored by era
geom_histogram(
binwidth = 5,
color = "white",
linewidth = 0.25
) +
# Era boundary lines
geom_vline(
xintercept = c(1660, 1800, 1837, 1901),
linetype = "dashed",
color = "gray50",
linewidth = 0.4
) +
# Era labels at top
annotate("text", x = 1530, y = Inf, label = "Early\nModern",
vjust = 1.3, hjust = 0.5, size = 3, color = "gray40", fontface = "italic") +
annotate("text", x = 1730, y = Inf, label = "Enlightenment",
vjust = 1.3, hjust = 0.5, size = 3, color = "gray40", fontface = "italic") +
annotate("text", x = 1818, y = Inf, label = "Romantic",
vjust = 1.3, hjust = 0.5, size = 3, color = "gray40", fontface = "italic") +
annotate("text", x = 1869, y = Inf, label = "Victorian",
vjust = 1.3, hjust = 0.5, size = 3.2, color = "gray30", fontface = "bold") +
annotate("text", x = 1925, y = Inf, label = "Modern",
vjust = 1.3, hjust = 0.5, size = 3, color = "gray40", fontface = "italic") +
# Famous author tick marks and labels
{
if (n_famous > 0) {
list(
geom_vline(
data = famous_authors,
aes(xintercept = birthdate),
color = "gray20",
linewidth = 0.5,
linetype = "solid",
inherit.aes = FALSE
),
geom_label(
data = famous_authors %>%
mutate(y_pos = annotation_heights),
aes(x = birthdate, y = y_pos, label = label),
size = 2.8,
fill = "white",
color = "gray20",
label.size = 0.2,
label.padding = unit(0.2, "lines"),
inherit.aes = FALSE
)
)
}
} +
scale_fill_manual(
values = setNames(as.character(era_palette), era_levels),
name = "Literary Era"
) +
scale_x_continuous(
breaks = seq(1400, 1950, by = 50),
labels = seq(1400, 1950, by = 50)
) +
scale_y_continuous(expand = expansion(mult = c(0, 0.12))) +
labs(
title = "**Project Gutenberg is a Victorian time capsule**",
subtitle = "Distribution of author birth years in the Gutenberg catalog, colored by literary era (binwidth = 5 years)",
x = "Author birth year",
y = "Number of authors",
caption = "Source: {gutenbergr} R package via TidyTuesday 2025-06-03 | Authors with unknown birth years excluded"
) +
theme_minimal(base_size = 13) +
theme(
plot.title = element_markdown(face = "bold", size = 16, margin = margin(b = 4)),
plot.subtitle = element_text(color = "gray40", size = 11, margin = margin(b = 10)),
plot.caption = element_text(color = "gray55", size = 9),
legend.position = "bottom",
legend.title = element_text(size = 10, face = "bold"),
legend.text = element_text(size = 9),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
axis.text = element_text(color = "gray40")
)
p_hero