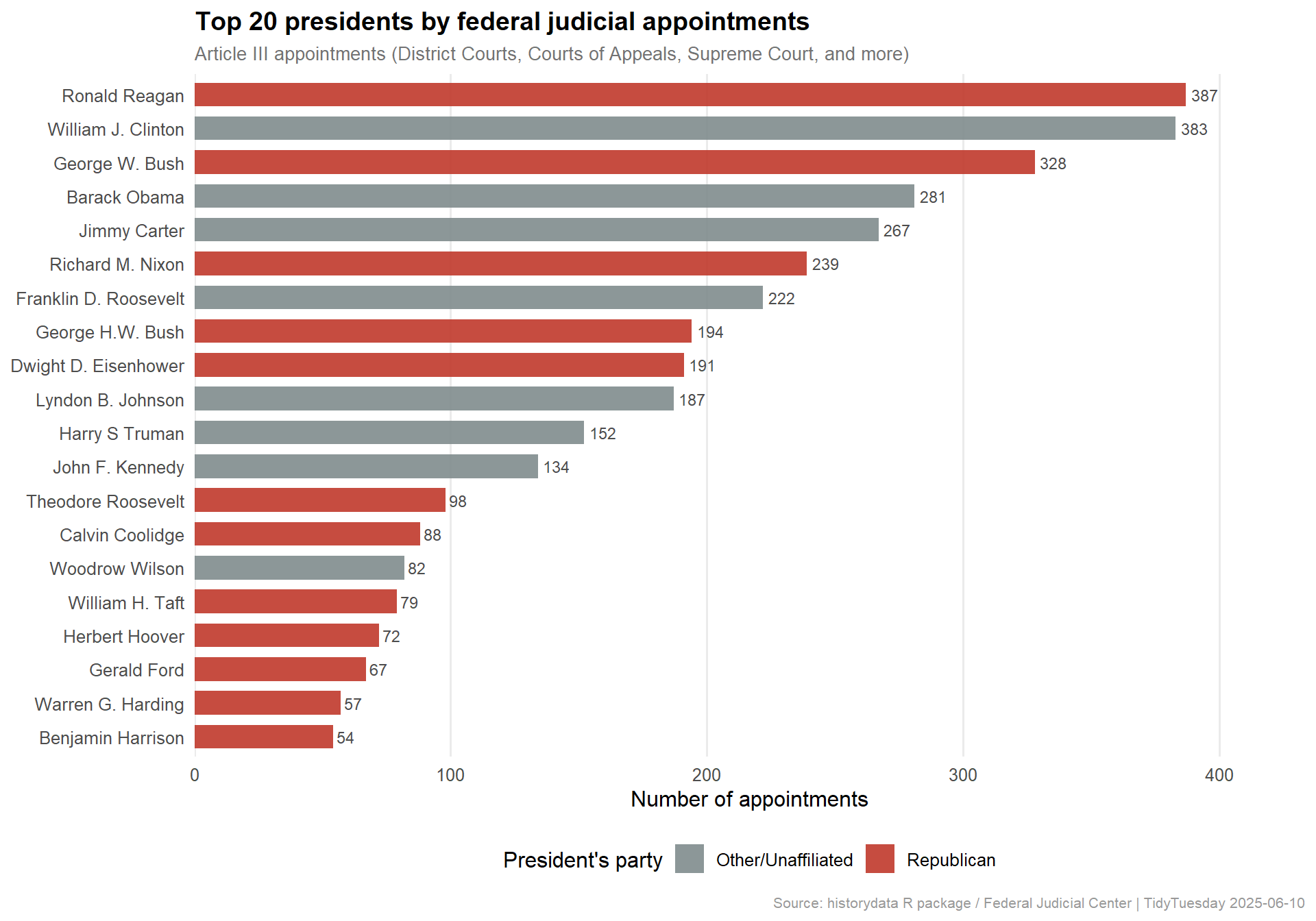
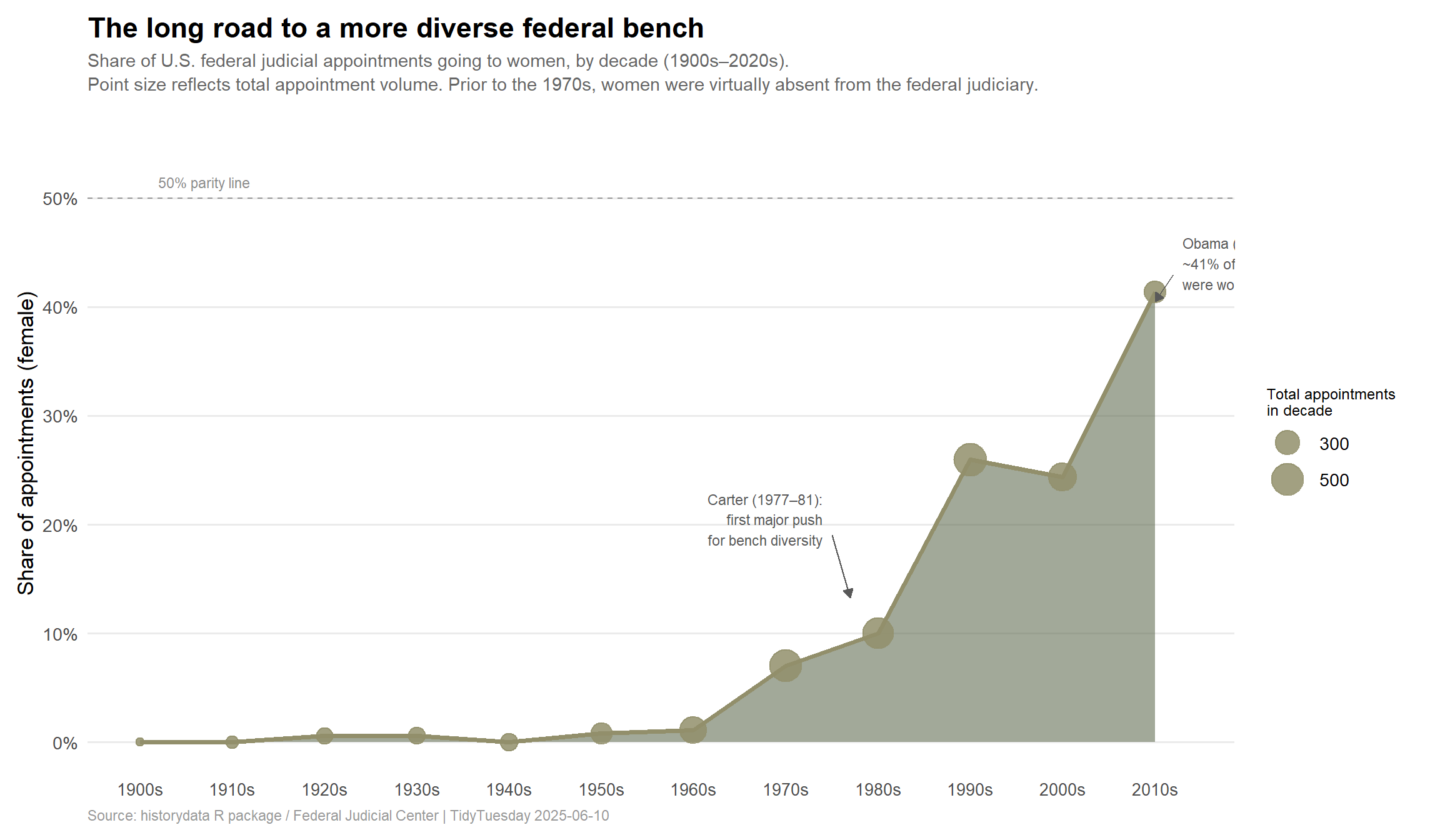
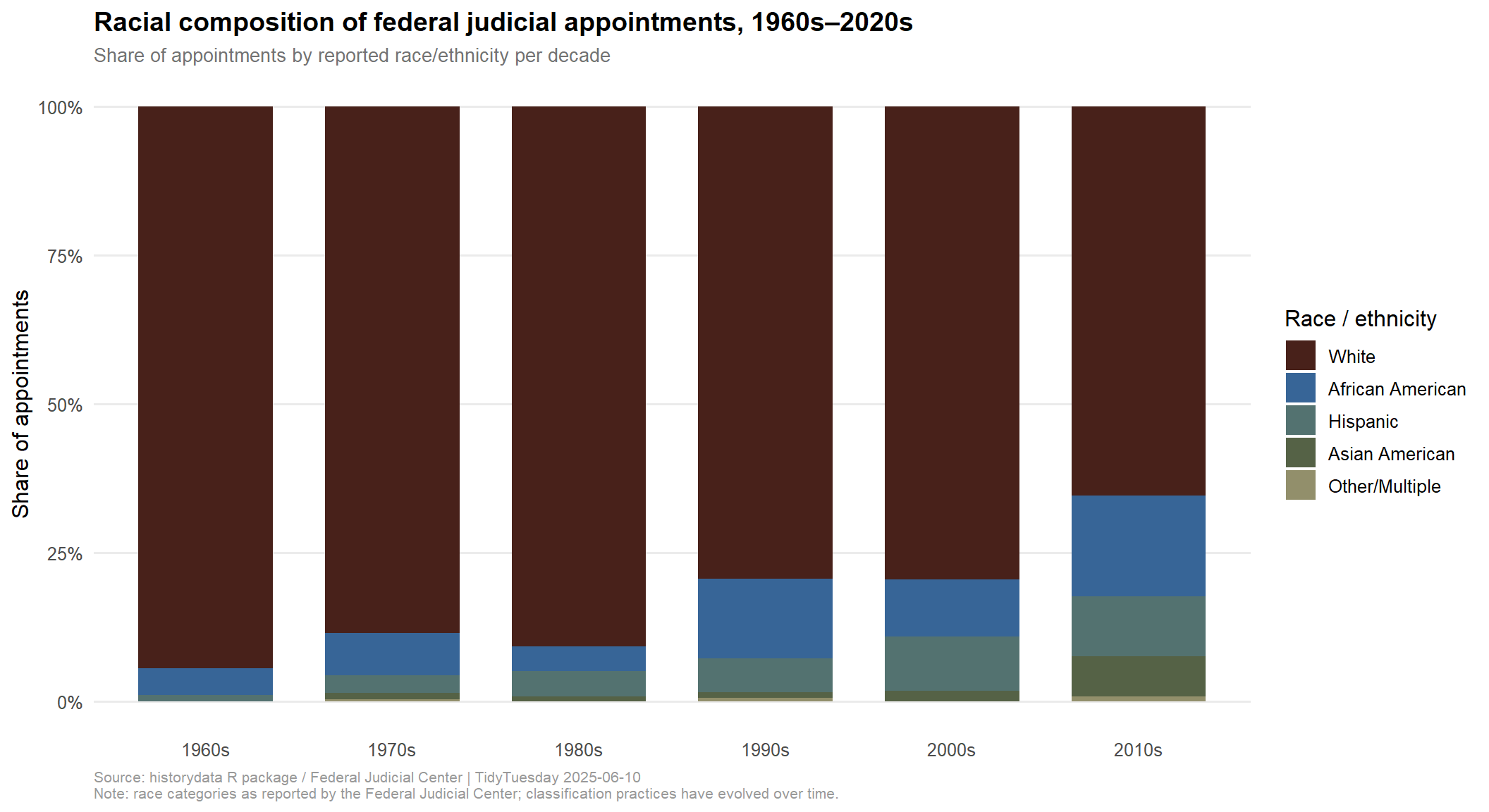
# Extract palette colors for single-series area chart
hero_pal <- paletteer::paletteer_d("dutchmasters::milkmaid")
fill_col <- hero_pal[4] # deep blue — primary fill
line_col <- hero_pal[5] # darker tone for line/points
annot_col <- "grey35"
# Annotation data for key administrations
annotations <- tibble::tribble(
~x, ~y, ~label, ~hjust,
1975, 0.22, "Carter (1977–81)\nlowest % white,\nhighest % women\nto that point", 1,
2008, 0.38, "Obama (2009–17)\n42% of appointments\nwere women", 0
)
p_hero <- female_pct_by_decade %>%
ggplot(aes(x = nom_decade, y = pct_female)) +
# Shaded area under the curve
geom_area(fill = fill_col, alpha = 0.55) +
# Reference line at 50%
geom_hline(
yintercept = 0.5,
linetype = "dashed",
color = "grey60",
linewidth = 0.5
) +
annotate(
"text", x = 1902, y = 0.515,
label = "50% parity line",
size = 3, hjust = 0, color = "grey55"
) +
# Trend line
geom_line(color = line_col, linewidth = 1.4) +
# Points sized by appointment volume
geom_point(
aes(size = total),
color = line_col,
alpha = 0.85
) +
# Carter annotation
annotate(
"segment",
x = 1975, xend = 1977, y = 0.19, yend = 0.133,
arrow = arrow(length = unit(0.2, "cm"), type = "closed"),
color = annot_col, linewidth = 0.5
) +
annotate(
"text",
x = 1974, y = 0.205,
label = "Carter (1977–81):\nfirst major push\nfor bench diversity",
size = 3, hjust = 1, color = annot_col, lineheight = 1.2
) +
# Obama annotation
annotate(
"segment",
x = 2012, xend = 2010, y = 0.43, yend = 0.405,
arrow = arrow(length = unit(0.2, "cm"), type = "closed"),
color = annot_col, linewidth = 0.5
) +
annotate(
"text",
x = 2013, y = 0.44,
label = "Obama (2009–17):\n~41% of appointments\nwere women",
size = 3, hjust = 0, color = annot_col, lineheight = 1.2
) +
scale_x_continuous(
breaks = seq(1900, 2020, by = 10),
labels = function(x) paste0(x, "s")
) +
scale_y_continuous(
labels = scales::percent_format(accuracy = 1),
limits = c(0, 0.55),
breaks = seq(0, 0.5, 0.1)
) +
scale_size_continuous(
range = c(2, 9),
name = "Total appointments\nin decade",
breaks = c(100, 300, 500, 800)
) +
labs(
title = "**The long road to a more diverse federal bench**",
subtitle = "Share of U.S. federal judicial appointments going to women, by decade (1900s–2020s).<br>
Point size reflects total appointment volume. Prior to the 1970s, women were virtually absent from the federal judiciary.",
x = NULL,
y = "Share of appointments (female)",
caption = "Source: historydata R package / Federal Judicial Center | TidyTuesday 2025-06-10"
) +
theme_minimal(base_size = 13) +
theme(
plot.title = element_markdown(face = "bold", size = 17, margin = margin(b = 6)),
plot.subtitle = element_markdown(color = "grey40", size = 11, lineheight = 1.3,
margin = margin(b = 12)),
plot.caption = element_text(color = "grey60", size = 8.5, hjust = 0),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
legend.position = "right",
legend.title = element_text(size = 9),
axis.text.x = element_text(size = 10),
plot.margin = margin(t = 10, r = 20, b = 10, l = 10)
)
p_hero