This week we’re exploring Web APIs! The dataset was curated by Jon Harmon while developing tools for creating API-wrapping R packages. The data comes from APIs.guru, whose goal is to create a “machine-readable Wikipedia for Web APIs in the OpenAPI Specification format.” Five tables cover API metadata, categories, logos, origin formats, and core specification details.
Suggested questions from the repo:
What API specs are provided by APIs.guru? Are these the same as the origin specs?
How many different APIs (“services”) do providers provide?
What licenses do APIs use?
Are any APIs listed more than once in the dataset?
Loading necessary packages
My handy booster pack that allows me to install (if needed) and load my usual and favorite packages, as well as some helpful functions.
The my_skim() function returns count, min, percentiles, mean, geometric mean, standard deviation, and an ASCII histogram.
apisguru_apis — the core catalog
This table has one row per API (filtered to the preferred version only), with timing metadata and spec version info. I drop swagger_url, link, external_docs_url, and external_docs_description since they are mostly URLs and free-text that won’t add to the numeric profile.
This table carries the richest semantic information. I drop free-text columns (description, contact_url, license_url, terms_of_service) that won’t contribute to the statistical profile, keeping the categorically interesting fields.
# A tibble: 20 × 2
apisguru_category n
<chr> <int>
1 cloud 955
2 media 340
3 open_data 318
4 analytics 284
5 developer_tools 168
6 ecommerce 78
7 financial 72
8 messaging 62
9 entertainment 61
10 telecom 60
11 text 57
12 location 51
13 collaboration 38
14 payment 32
15 transport 29
16 hosting 20
17 security 19
18 iot 18
19 social 18
20 tools 16
api_origins — source spec formats
api_origins %>%count(format, sort =TRUE)
# A tibble: 7 × 2
format n
<chr> <int>
1 swagger 1060
2 openapi 923
3 <NA> 272
4 google 258
5 postman 15
6 wadl 5
7 apiBlueprint 3
The EDA reveals several things at a glance. The apisguru_apis catalog spans thousands of APIs with added dates spread over many years. The api_info table confirms that provider_name is the key grouping variable — providers supply anywhere from one to hundreds of services. Licenses are sparsely populated (many NAs), suggesting the API ecosystem is not yet mature in its licensing practices. In api_origins, swagger dominates as the original spec format, followed by openapi and google (Google Discovery).
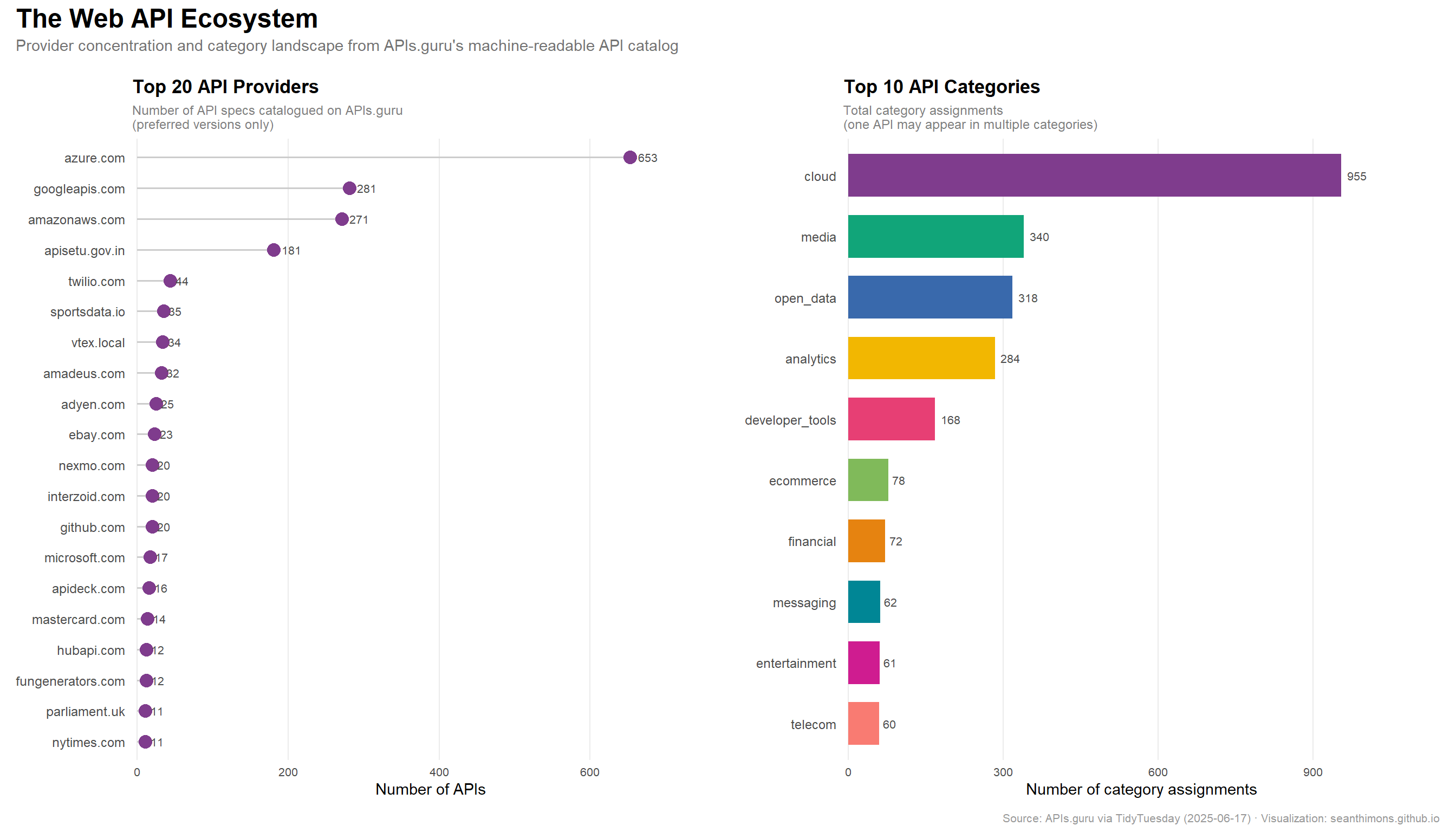
The Web API Ecosystem
Provider concentration: the long tail of API supply
How many APIs does each provider offer? The hypothesis is a classic power-law distribution: a handful of mega-providers (Amazon, Google, Microsoft) supply hundreds of APIs, while the vast majority of providers supply just one.
The concentration is striking. The top provider alone offers tens to hundreds of API versions, while the majority of providers in the catalog contribute just a single spec. This is a textbook Pareto distribution — the “API ecosystem” looks like a busy marketplace only from the outside.
Category landscape
APIs.guru categorizes APIs with a many-to-many mapping — one API can belong to multiple categories. The counts below reflect total category assignments, not unique APIs.
# A tibble: 15 × 2
license_name n_apis
<chr> <int>
1 (none / unlisted) 1643
2 Creative Commons Attribution 3.0 285
3 Apache 2.0 License 273
4 Apache 2.0 109
5 MIT 51
6 eBay API License Agreement 25
7 Interzoid license 20
8 The MIT License (MIT) 7
9 Open Government License - British Columbia 6
10 U.S. Public Domain License 6
11 MIT License 4
12 open-licence 4
13 Apache-2.0 3
14 BSD-3-Clause 3
15 API available under GNU Lesser General Public License 2
Important
The large proportion of APIs without a stated license reflects a recurring gap in the API ecosystem — many providers publish specs without explicit licensing terms, creating ambiguity for developers building on top of them.
Spec format: origin vs. APIs.guru’s served version
APIs.guru converts all ingested specs to OpenAPI format. This means an API originally written in Postman, WADL, or Google Discovery gets normalized and served in a common format. The api_origins table captures the original format, while apisguru_apis$openapi_ver reflects what APIs.guru actually serves.
# Original spec formatsorigin_formats <- api_origins %>%filter(!is.na(format)) %>%count(format, sort =TRUE, name ="n_specs") %>%mutate(pct =round(100* n_specs /sum(n_specs), 1))cat("Origin formats:\n")
Swagger → OpenAPI: The original format breakdown shows swagger-dominated origins, but APIs.guru also serves swagger 2.0 specs directly. The migration to OpenAPI 3.x is underway but not yet the majority — the ecosystem carries significant legacy.
Hero visualization: The Web API Ecosystem at a Glance
# --- palette --------------------------------------------------------------# rcartocolor::Bold — 12 distinct colors, not previously usedcat_palette <-as.character(paletteer::paletteer_d("rcartocolor::Bold"))provider_accent <- cat_palette[1] # single accent for provider bars# --- panel 1: top 20 providers -------------------------------------------top20_providers <- provider_counts %>%head(20) %>%mutate(provider_name =fct_reorder(provider_name, n_apis))cat(sprintf("top20_providers: %d rows\n", nrow(top20_providers)))
top20_providers: 20 rows
stopifnot("top20_providers is empty"=nrow(top20_providers) >0)p1 <-ggplot(top20_providers,aes(x = n_apis, y = provider_name)) +geom_segment(aes(x =0, xend = n_apis,y = provider_name, yend = provider_name),color ="grey80", linewidth =0.6) +geom_point(size =4, color = provider_accent) +geom_text(aes(label = n_apis),hjust =-0.4, size =2.8, color ="grey30", family ="sans") +scale_x_continuous(expand =expansion(mult =c(0.01, 0.2))) +labs(title ="Top 20 API Providers",subtitle ="Number of API specs catalogued on APIs.guru\n(preferred versions only)",x ="Number of APIs",y =NULL ) +theme_minimal(base_size =11) +theme(plot.title =element_text(face ="bold", size =13),plot.subtitle =element_text(color ="grey50", size =9),panel.grid.major.y =element_blank(),panel.grid.minor =element_blank(),axis.text.y =element_text(size =9),axis.text.x =element_text(size =8) )# --- panel 2: top 10 categories ------------------------------------------top10_cats <- category_counts %>%head(10) %>%mutate(apisguru_category =fct_reorder(apisguru_category, n_apis),fill_color = cat_palette[seq_len(n())] )cat(sprintf("top10_cats: %d rows\n", nrow(top10_cats)))
top10_cats: 10 rows
stopifnot("top10_cats is empty"=nrow(top10_cats) >0)p2 <-ggplot(top10_cats,aes(x = n_apis, y = apisguru_category, fill = apisguru_category)) +geom_col(width =0.7, show.legend =FALSE) +geom_text(aes(label = n_apis),hjust =-0.3, size =2.8, color ="grey30", family ="sans") +scale_fill_manual(values =setNames(top10_cats$fill_color, top10_cats$apisguru_category)) +scale_x_continuous(expand =expansion(mult =c(0.01, 0.2))) +labs(title ="Top 10 API Categories",subtitle ="Total category assignments\n(one API may appear in multiple categories)",x ="Number of category assignments",y =NULL ) +theme_minimal(base_size =11) +theme(plot.title =element_text(face ="bold", size =13),plot.subtitle =element_text(color ="grey50", size =9),panel.grid.major.y =element_blank(),panel.grid.minor =element_blank(),axis.text.y =element_text(size =9),axis.text.x =element_text(size =8) )# --- combine with patchwork ----------------------------------------------p <- p1 + p2 +plot_annotation(title ="The Web API Ecosystem",subtitle ="Provider concentration and category landscape from APIs.guru's machine-readable API catalog",caption ="Source: APIs.guru via TidyTuesday (2025-06-17) · Visualization: seanthimons.github.io",theme =theme(plot.title =element_text(face ="bold", size =18, margin =margin(b =4)),plot.subtitle =element_text(color ="grey45", size =11, margin =margin(b =12)),plot.caption =element_text(color ="grey60", size =8, hjust =1),plot.background =element_rect(fill ="white", color =NA) ) )p
Final thoughts and takeaways
The APIs.guru catalog is a snapshot of the public web API ecosystem in miniature — and it has the shape of almost every other technology ecosystem: power-law concentrated at the top, extraordinarily long-tailed below.
A single hyperscaler (Amazon Web Services, by most accounts) accounts for a disproportionate share of catalogued APIs. But this metric flatters the giants: one AWS region expanding its service surface area adds dozens of specs. The far more numerous single-API providers represent the quiet majority — independent developers, regional SaaS companies, and niche services that collectively outnumber the platform giants by a wide margin.
The category landscape confirms what the cloud era has wrought: “Cloud” and developer tooling dominate, followed by communication and IoT categories that reflect the proliferation of connected infrastructure. The long tail of the category chart captures verticals still in the early innings of API standardization.
The licensing gap is perhaps the most actionable finding. A large fraction of APIs in the catalog carry no stated license. For developers building client libraries or wrappers — exactly the use case Jon Harmon is addressing with his package ecosystem — that ambiguity matters. The rise of OpenAPI as a standardized spec format is one half of the interoperability story; clear licensing is the other half that the ecosystem hasn’t yet solved.
Finally, the spec format transition tells a gradualist story. Swagger 2.0 remains deeply embedded in the ecosystem’s origin history, but APIs.guru’s normalization layer and the slow uptick in OpenAPI 3.x adoption suggest the industry is moving — just not quickly.