BYOD week — revisiting the Coffee Quality Institute dataset to explore what makes a great cup of coffee, from altitude to aroma scores.
Author
Sean Thimons
Published
January 6, 2026
Preface
This is a Bring Your Own Data week for TidyTuesday! I’m revisiting the Coffee Quality Institute dataset originally featured in TidyTuesday on July 7, 2020.
The Coffee Quality Institute (CQI) maintains a database of coffee quality scores from trained reviewers. Each coffee sample is rated on multiple attributes including aroma, flavor, aftertaste, acidity, body, balance, uniformity, clean cup, sweetness, and overall quality. The dataset also includes origin metadata like country, altitude, and processing method.
Loading necessary packages
My handy booster pack that allows me to install (if needed) and load my usual and favorite packages, as well as some helpful functions.
raw <- tidytuesdayR::tt_load('2020-07-07')coffee <- raw$coffee_ratings
Exploratory Data Analysis
The my_skim() function is a modified version of the skimr::skim() function that returns the number of missing data points (cells as NA) as well as the inverse (e.g.: number of rows that are notNA), the count, minimum, 25%, median, 75%, max, mean, geometric mean, and standard deviation. It also generates a little ASCII histogram. Neat!
Coffee Ratings
I’ll focus on the quality scoring columns and key origin metadata, dropping free-text and identifier fields.
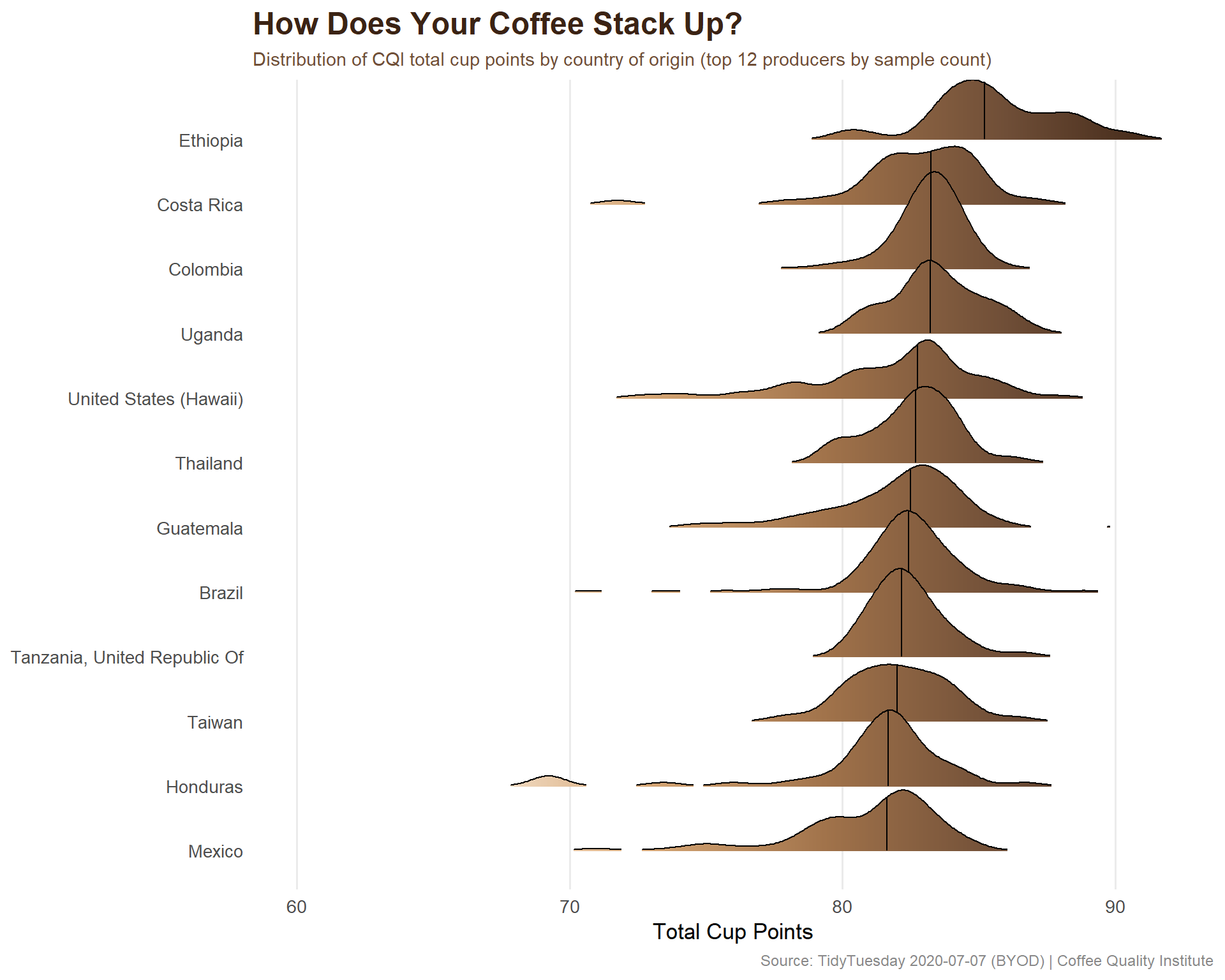
The hero plot shows the distribution of quality scores across the top coffee-producing countries as ridge plots, with a warm coffee-inspired color palette.
# Coffee-inspired palette — light roast to dark roastcoffee_gradient <-c("#F5E6D3", # cream"#D4A574", # light roast"#A0724A", # medium roast"#6F4E37", # dark roast"#3B2314"# espresso)# Get top 12 countries by sample counttop_countries <- coffee %>%filter(total_cup_points >0) %>%count(country_of_origin, sort =TRUE) %>%head(12) %>%pull(country_of_origin)plot_data <- coffee %>%filter( country_of_origin %in% top_countries, total_cup_points >50 ) %>%mutate(country_of_origin =fct_reorder(country_of_origin, total_cup_points, .fun = median) )# Calculate medians for annotationcountry_medians <- plot_data %>%group_by(country_of_origin) %>%summarize(med =median(total_cup_points), .groups ="drop")ggplot(plot_data, aes(x = total_cup_points, y = country_of_origin, fill =after_stat(x))) +geom_density_ridges_gradient(scale =1.5,rel_min_height =0.01,quantile_lines =TRUE,quantiles =2 ) +scale_fill_gradientn(colors = coffee_gradient,name ="Cup Points" ) +scale_x_continuous(limits =c(60, 92)) +labs(title ="How Does Your Coffee Stack Up?",subtitle ="Distribution of CQI total cup points by country of origin (top 12 producers by sample count)",x ="Total Cup Points",y =NULL,caption ="Source: TidyTuesday 2020-07-07 (BYOD) | Coffee Quality Institute" ) +theme_minimal(base_size =13) +theme(plot.title =element_text(face ="bold", size =18, color ="#3B2314"),plot.subtitle =element_text(size =11, color ="#6F4E37"),plot.caption =element_text(size =9, color ="#888888"),legend.position ="none",panel.grid.minor =element_blank(),panel.grid.major.y =element_blank() )
Final thoughts and takeaways
The Coffee Quality Institute data reveals a fascinating picture of what drives coffee quality scores. The most immediate finding is how tightly clustered the scores are — most reviewed coffees land between 75 and 88 total cup points, which makes sense given that CQI reviews tend to evaluate specialty-grade coffee that has already passed initial quality screens.
Among the quality attributes, flavor and aftertaste show the highest coefficient of variation, meaning they’re the dimensions where coffees differentiate themselves most. Aroma and body, by contrast, are more consistent across samples. This suggests that if you’re evaluating a coffee, the lingering finish and primary flavor notes are where the real action is.
The altitude-quality correlation, while statistically present, is modest. Higher-altitude farms do tend to produce slightly higher-rated coffees, but altitude alone doesn’t explain the variance nearly as much as origin country and processing method. The coffee industry’s obsession with altitude as a quality signal is somewhat overstated by the data.
Tip
For home coffee enthusiasts: the processing method (washed vs. natural vs. honey) often has a bigger impact on your cup than altitude or even country of origin. If you want to explore flavor differences, try the same origin processed two different ways — it’s the fastest path to understanding what you personally value in a cup.