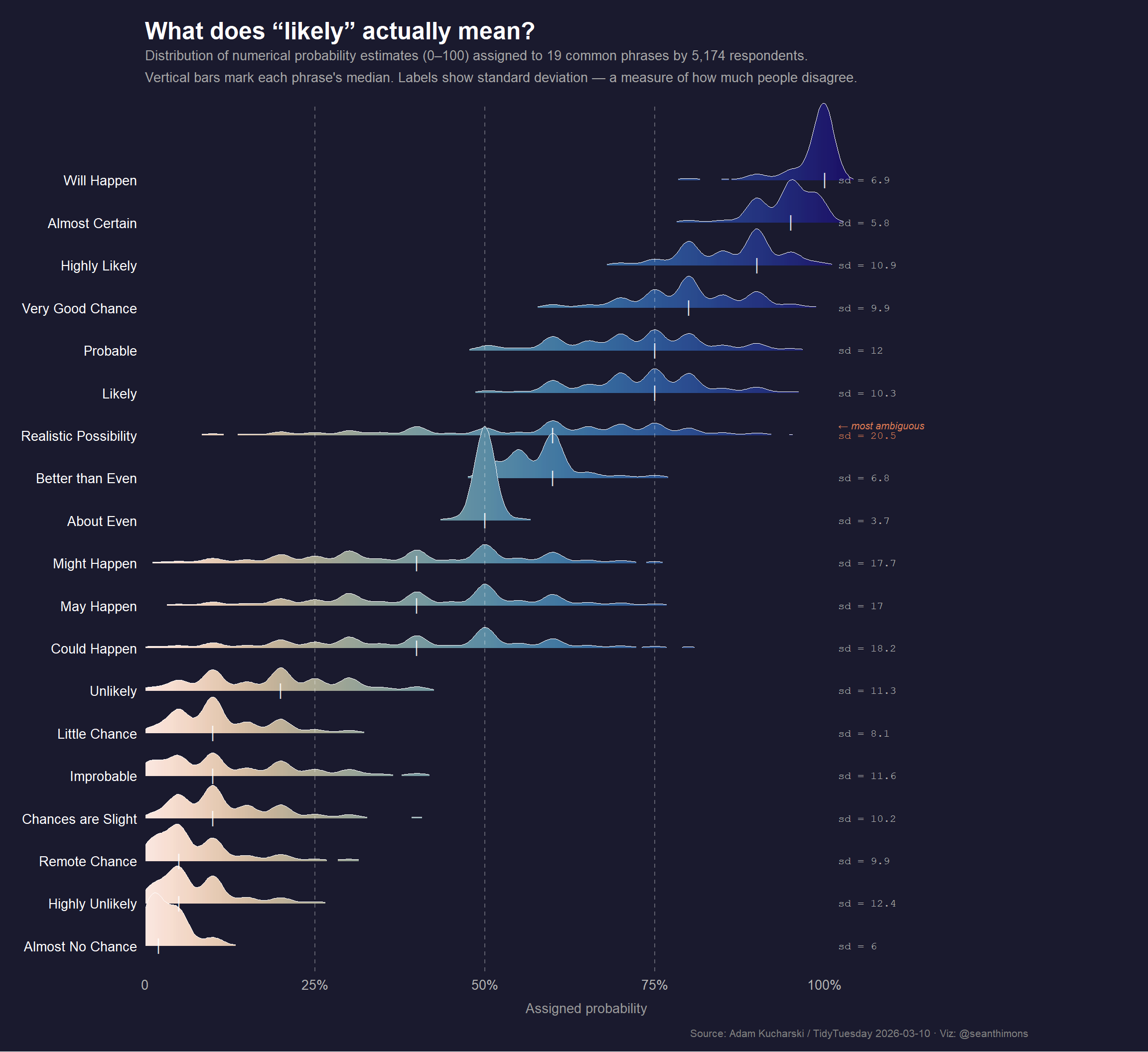
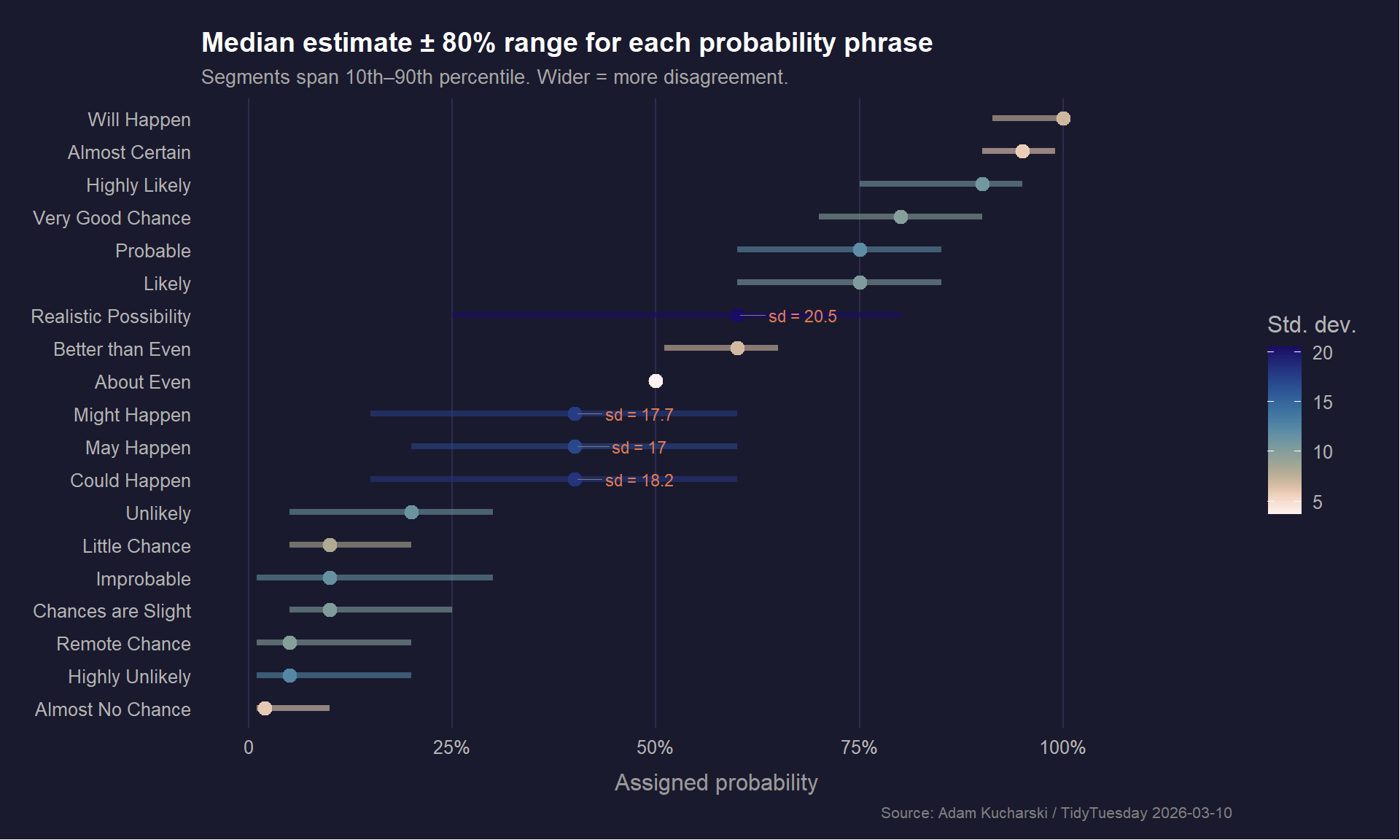
p <- ggplot2::ggplot(plot_data,
ggplot2::aes(
x = probability,
y = term,
fill = ggplot2::after_stat(x)
)
) +
# Ridge plot with gradient fill — each ridge's color encodes the x-value
ggridges::geom_density_ridges_gradient(
scale = 2.2,
rel_min_height = 0.01,
color = "white",
linewidth = 0.35,
show.legend = FALSE
) +
# Median tick marks
ggplot2::geom_point(
data = annot_data,
mapping = ggplot2::aes(x = median_prob, y = term),
inherit.aes = FALSE,
shape = 124, # vertical bar
size = 4,
color = "white",
alpha = 0.85
) +
# SD annotation — right-aligned labels
ggplot2::geom_text(
data = annot_data,
mapping = ggplot2::aes(
x = 102,
y = term,
label = sprintf("sd = %g", sd_prob),
color = is_ambiguous
),
inherit.aes = FALSE,
hjust = 0,
vjust = 0.5,
size = 2.8,
family = "mono",
fontface = "plain",
show.legend = FALSE
) +
# Highlight "Realistic Possibility" annotation
ggplot2::annotate(
"text",
x = 102,
y = "Realistic Possibility",
label = "← most ambiguous",
vjust = -0.8,
hjust = 0,
size = 2.6,
color = "#E07B54",
fontface = "italic"
) +
# Reference lines at 25 / 50 / 75
ggplot2::geom_vline(
xintercept = c(25, 50, 75),
linetype = "dashed",
color = "white",
alpha = 0.3,
linewidth = 0.4
) +
# Gradient fill using scico::lapaz (unused palette — blue-purple to cream)
paletteer::scale_fill_paletteer_c("scico::lapaz", direction = -1) +
# Color for SD label (highlight ambiguous term)
ggplot2::scale_color_manual(
values = c(`FALSE` = "grey70", `TRUE` = "#E07B54")
) +
# x-axis labels at reference lines
ggplot2::scale_x_continuous(
limits = c(0, 130),
breaks = c(0, 25, 50, 75, 100),
labels = c("0", "25%", "50%", "75%", "100%"),
expand = ggplot2::expansion(mult = c(0, 0))
) +
ggplot2::labs(
title = "**What does \"likely\" actually mean?**",
subtitle = "Distribution of numerical probability estimates (0–100) assigned to 19 common phrases by 5,174 respondents.\nVertical bars mark each phrase's median. Labels show standard deviation — a measure of how much people disagree.",
x = "Assigned probability",
y = NULL,
caption = "Source: Adam Kucharski / TidyTuesday 2026-03-10 · Viz: @seanthimons"
) +
ggplot2::theme_minimal(base_size = 13) +
ggplot2::theme(
plot.background = ggplot2::element_rect(fill = "#1a1a2e", color = NA),
panel.background = ggplot2::element_rect(fill = "#1a1a2e", color = NA),
panel.grid.major.x = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank(),
panel.grid.major.y = ggplot2::element_blank(),
axis.text.x = ggplot2::element_text(color = "grey70", size = 10),
axis.text.y = ggplot2::element_text(color = "white", size = 10, hjust = 1),
axis.title.x = ggplot2::element_text(color = "grey60", size = 10, margin = ggplot2::margin(t = 8)),
plot.title = ggtext::element_markdown(color = "white", size = 18, face = "bold", margin = ggplot2::margin(b = 4)),
plot.subtitle = ggplot2::element_text(color = "grey65", size = 10, lineheight = 1.4, margin = ggplot2::margin(b = 14)),
plot.caption = ggplot2::element_text(color = "grey50", size = 8, hjust = 1, margin = ggplot2::margin(t = 10)),
plot.margin = ggplot2::margin(16, 90, 10, 16)
)
p