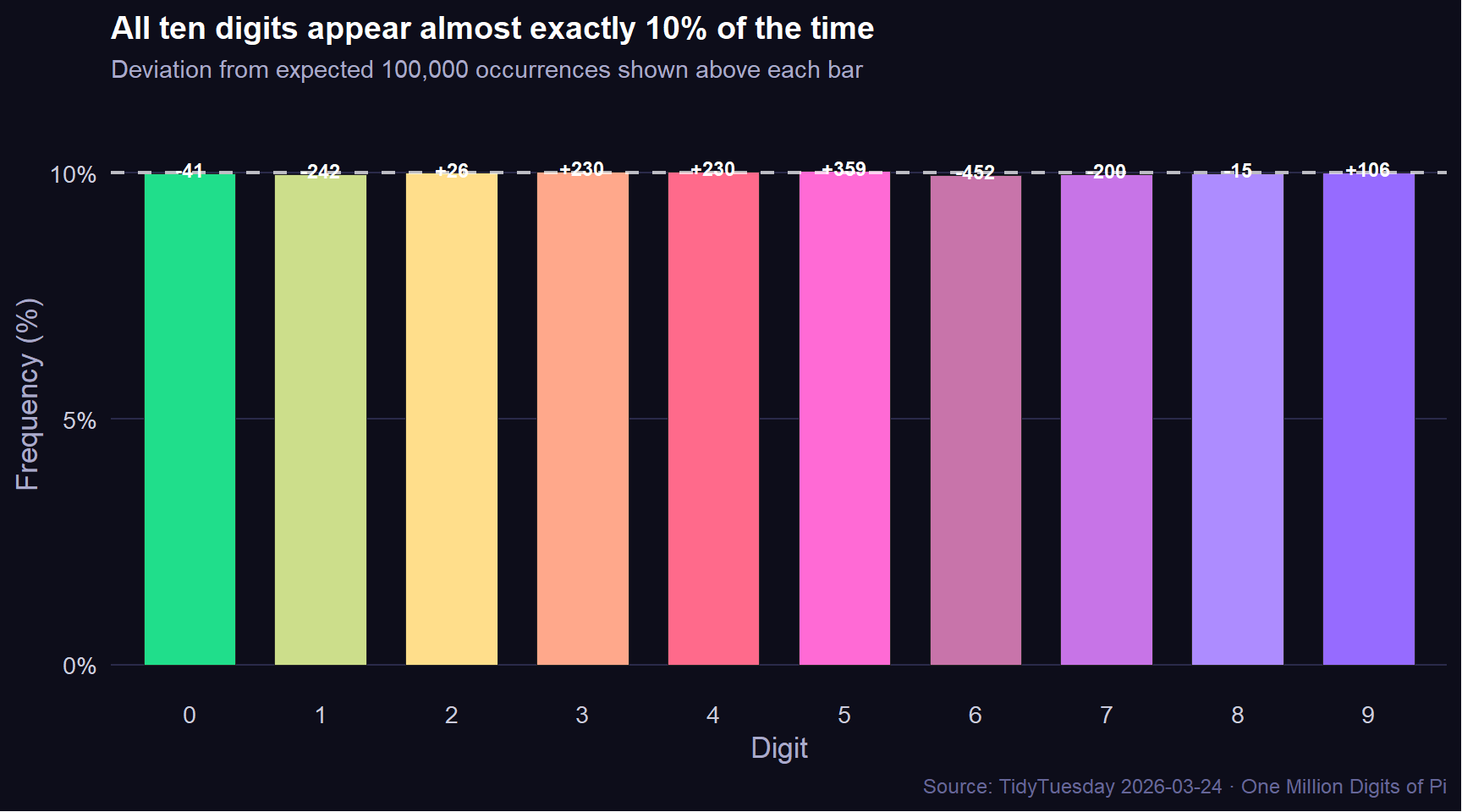
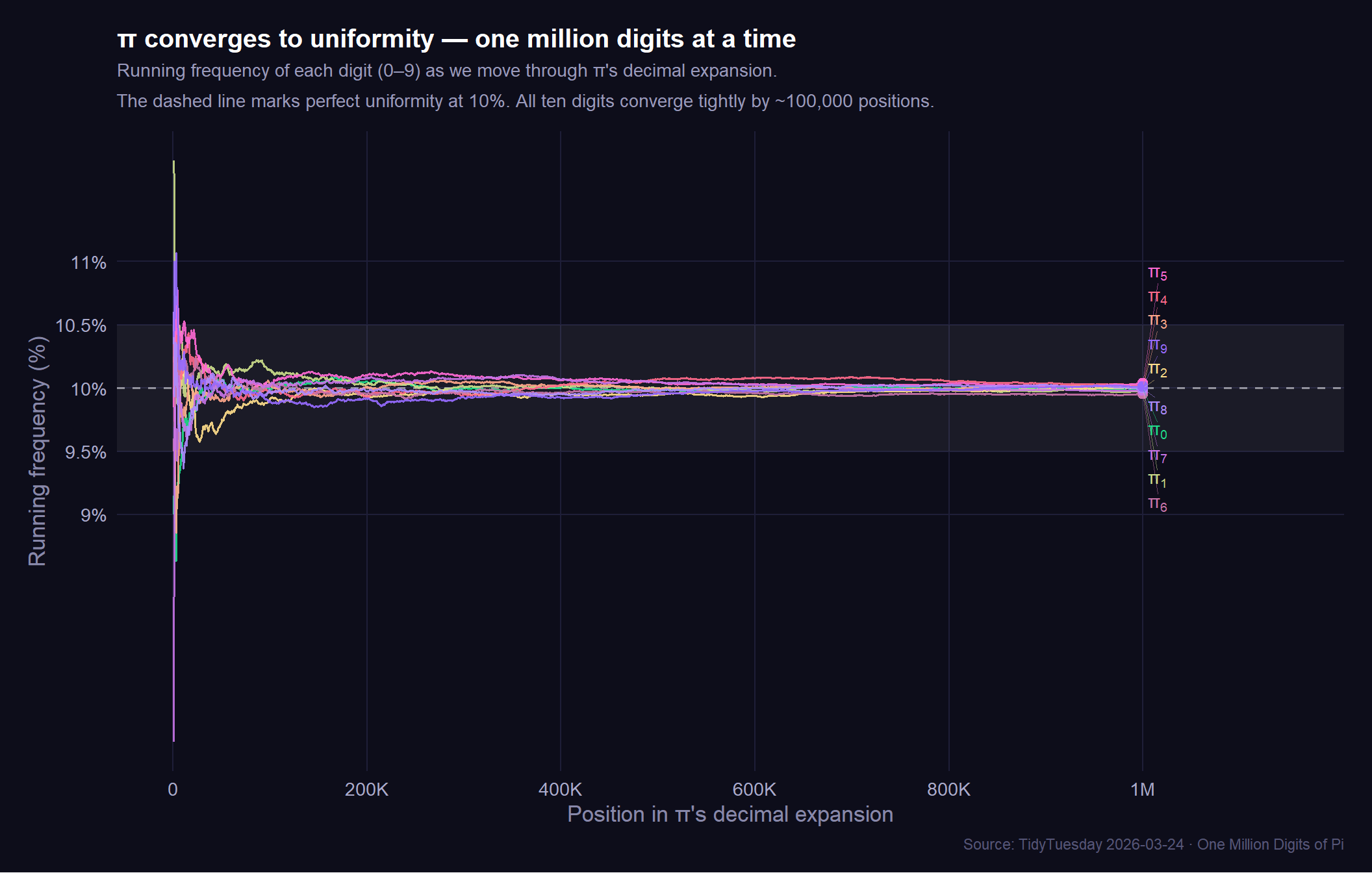
# Endpoint labels for annotation
endpoints <- running_freq %>%
group_by(digit) %>%
filter(checkpoint == max(checkpoint)) %>%
ungroup()
p_convergence <- running_freq %>%
ggplot2::ggplot(ggplot2::aes(
x = checkpoint / 1000,
y = running_pct,
color = digit,
group = digit
)) +
# Reference band: +/- 0.5% around 10%
ggplot2::annotate(
"rect",
xmin = -Inf, xmax = Inf,
ymin = 9.5, ymax = 10.5,
fill = "white", alpha = 0.06
) +
# Perfect uniformity line
ggplot2::geom_hline(
yintercept = 10,
linetype = "dashed",
color = "white",
linewidth = 0.6,
alpha = 0.5
) +
ggplot2::geom_line(linewidth = 0.65, alpha = 0.9) +
# Endpoint dots
ggplot2::geom_point(
data = endpoints,
ggplot2::aes(x = checkpoint / 1000, y = running_pct),
size = 2.5
) +
# Digit labels at the end
ggrepel::geom_text_repel(
data = endpoints,
ggplot2::aes(
x = checkpoint / 1000,
y = running_pct,
label = paste0("π[", digit, "]"),
color = digit
),
parse = TRUE,
size = 3.5,
fontface = "bold",
direction = "y",
nudge_x = 15,
segment.size = 0.3,
segment.alpha = 0.5,
min.segment.length = 0.2,
box.padding = 0.2,
max.overlaps = 20,
show.legend = FALSE
) +
ggplot2::scale_color_manual(values = pi_palette) +
ggplot2::scale_x_continuous(
limits = c(0, 1150),
breaks = c(0, 200, 400, 600, 800, 1000),
labels = c("0", "200K", "400K", "600K", "800K", "1M")
) +
ggplot2::scale_y_continuous(
breaks = c(9, 9.5, 10, 10.5, 11),
labels = c("9%", "9.5%", "10%", "10.5%", "11%")
) +
ggplot2::labs(
title = "π converges to uniformity — one million digits at a time",
subtitle = "Running frequency of each digit (0–9) as we move through π's decimal expansion.\nThe dashed line marks perfect uniformity at 10%. All ten digits converge tightly by ~100,000 positions.",
x = "Position in π's decimal expansion",
y = "Running frequency (%)",
caption = "Source: TidyTuesday 2026-03-24 · One Million Digits of Pi"
) +
ggplot2::theme_minimal(base_size = 13) +
ggplot2::theme(
plot.background = ggplot2::element_rect(fill = "#0d0d1a", color = NA),
panel.background = ggplot2::element_rect(fill = "#0d0d1a", color = NA),
panel.grid.major = ggplot2::element_line(color = "#1e1e38", linewidth = 0.4),
panel.grid.minor = ggplot2::element_blank(),
text = ggplot2::element_text(color = "white"),
plot.title = ggplot2::element_text(
color = "white", face = "bold", size = 15, margin = ggplot2::margin(b = 6)
),
plot.subtitle = ggplot2::element_text(
color = "#9999bb", size = 10.5, lineheight = 1.4,
margin = ggplot2::margin(b = 12)
),
plot.caption = ggplot2::element_text(color = "#555577", size = 8.5),
axis.text = ggplot2::element_text(color = "#aaaacc"),
axis.title = ggplot2::element_text(color = "#8888aa"),
legend.position = "none",
plot.margin = ggplot2::margin(16, 16, 12, 16)
)
p_convergence